
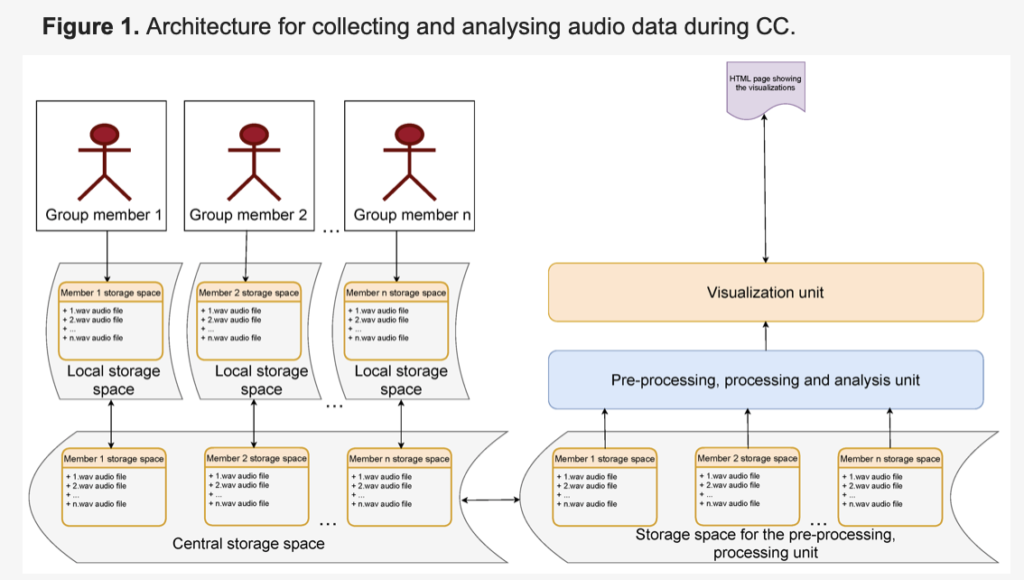
 Collaboration is an important 21st Century skill. Co-located (or face-to-face) collaboration (CC) analytics gained momentum with the advent of sensor technology. Most of these works have used the audio modality to detect the quality of CC. The CC quality can be detected from simple indicators of collaboration such as total speaking time or complex indicators like synchrony in the rise and fall of the average pitch. Most studies in the past focused on “how group members talk” (i.e., spectral, temporal features of audio like pitch) and not “what they talk”. The “what” of the conversations is more overt contrary to the “how” of the conversations. Very few studies studied “what” group members talk about, and these studies were lab based showing a representative overview of specific words as topic clusters instead of analysing the richness of the content of the conversations by understanding the linkage between these words. To overcome this, we made a starting step in this technical paper based on field trials to prototype a tool to move towards automatic collaboration analytics. We designed a technical setup to collect, process and visualize audio data automatically.
Collaboration is an important 21st Century skill. Co-located (or face-to-face) collaboration (CC) analytics gained momentum with the advent of sensor technology. Most of these works have used the audio modality to detect the quality of CC. The CC quality can be detected from simple indicators of collaboration such as total speaking time or complex indicators like synchrony in the rise and fall of the average pitch. Most studies in the past focused on “how group members talk” (i.e., spectral, temporal features of audio like pitch) and not “what they talk”. The “what” of the conversations is more overt contrary to the “how” of the conversations. Very few studies studied “what” group members talk about, and these studies were lab based showing a representative overview of specific words as topic clusters instead of analysing the richness of the content of the conversations by understanding the linkage between these words. To overcome this, we made a starting step in this technical paper based on field trials to prototype a tool to move towards automatic collaboration analytics. We designed a technical setup to collect, process and visualize audio data automatically.

The data collection took place while our FoLA2, a board game method (Schmitz, Scheffel, Bemelmans, & Drachsler, 2020), was played among the university staff with pre-assigned roles to create awareness of the connection between learning analytics and learning design. We not only did a word-level analysis of the conversations, but also analysed the richness of these conversations by visualizing the strength of the linkage between these words and phrases interactively. In this visualization, we used a network graph to visualize turn taking exchange between different roles along with the word-level and phrase-level analysis. We also used centrality measures to understand the network graph further based on how much words have hold over the network of words and how influential are certain words. Finally, we found that this approach had certain limitations in terms of automation in speaker diarization (i.e., who spoke when) and text data pre-processing.
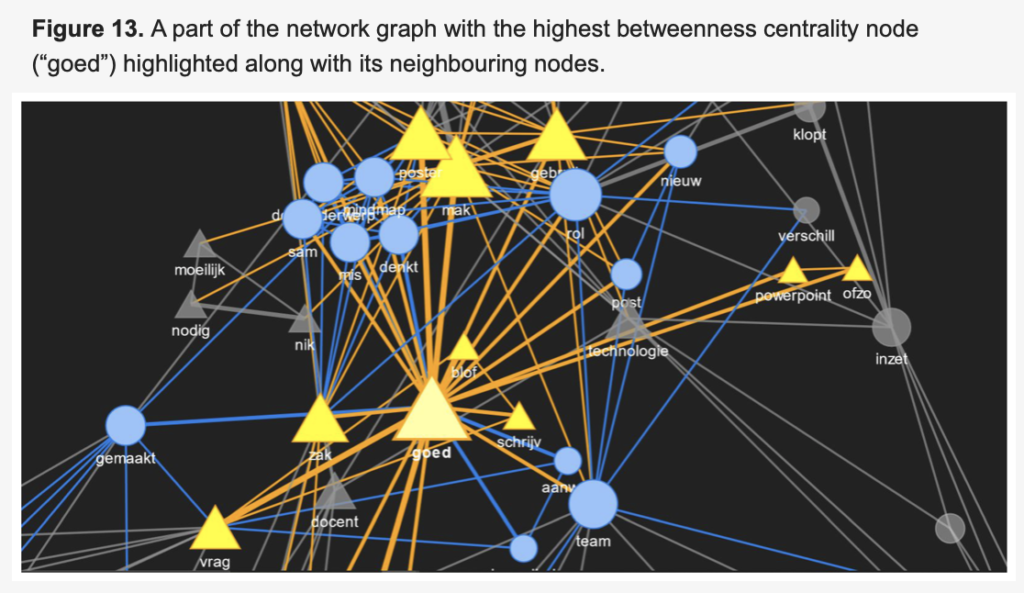
Therefore, we concluded that even though the technical setup was partially automated, it is a way forward to understand the richness of the conversations between different roles and makes a significant step towards automatic collaboration analytics.
Reference:
- Praharaj, S.; Scheffel, M.; Schmitz, M.; Specht, M.; and Drachsler, H. (2021). Towards Automatic Collaboration Analytics for Group Speech Data Using Learning Analytics. Sensors 2021, 21, 3156. https://doi.org/10.3390/s21093156